ども、@kimihom です。

先日の CallConnect リリースで、文字化した話者の判断ができるようになった。文字化を見た瞬間に、どちらが担当者で、どちらが顧客の発言かを、すぐに判断できるようになった。これにより、録音音声をわざわざ聞かなくとも、文字化を読むだけで内容をより正確に把握できるようになった。
ここまでに至るには長いTwilioとの実装やりとり、そしてAmazon Transcribe への操作が必要で、本記事ではその流れについて紹介しようと思う。
録音ファイルの自前管理
まず音声を文字化をする上で、元の音声をどこに置くかを決める必要がある。これから始める場合には、Twilio が今年リリースした Twilio Voiceの通話録音向け外部ストレージ機能 を使うのが一番早い。Twilio 側で AWS S3 の認証情報を貼り付けるだけで、勝手に S3 へ書き出されるようになる。これが出てくる前までは、わざわざ録音をDLして新しく自前S3にアップロードさせる実装が必須であったが、便利になったものである。
Twilio の標準の書き出し先が Amazon S3 である以上、音声の文字化も 同じ AWS にある Transcribe を使うというのは一般的な判断となろう。
もちろん、Amazon Transcribe 以外にも音声を文字化する外部サービスは複数あるので、実際に文字化した時のクオリティに関しては事前に確認しておいた方がいいに違いない。
Transcribe での文字化結果
では Twilio から AWS S3 の録音URL を取ってきて、録音再生までできるようになったとした時、どんな流れで実装していくのかを簡単に示そう。
Amazon Transcribe へリクエスト送信
まずは録音URL を指定して、文字化するリクエストを送る。
const transcribe = new AWS.TranscribeService(); // 新規作成依頼 let name = "一意な名前"; transcribe.startTranscriptionJob({ "LanguageCode": "ja-JP", "Media": { "MediaFileUri": voiceUrl }, "TranscriptionJobName": name, "MediaFormat": "wav", "Settings": { "ChannelIdentification": true, "ShowAlternatives": false } }, function(err, data) { console.log(data); }); // 完了した時に一覧を取得 let jobs = transcribe.listTranscriptionJobs({ status: "COMPLETED" }) // 個別に詳細を取得.. jobs.forEach(n => { let job = transcribe.getTranscriptionJob({ transcription_job_name: n.transcriptionJobName }) // job.transcriptionJob.transcript.transcriptFileUri に結果が入っている })
ここで大事なのは ChannelIdentification を指定し、話者の識別を有効にさせる必要がある。そして、AWS 側では誰が担当者で誰が顧客かの判断は不可能であることがわかるという点にある。
そのため、録音を作った時点で、どっちの発言がどっちであることを識別しておかないといけないことになる。ここが今回のキーポイント。
録音URL を保存する時点で、通話の種類から話者を判断
話者の判断のために、Twilio 側で通話を終了した時点で、どちらが最初に通話の接続をしたのかに関するデータ保存が必要だ。
基本的には「通話に入ってきた順」であることがわかった。つまり、最初に発信した方が channel[0] に入り、後が channel[1] に入るというだけとなる。担当者が発進して顧客が電話に受けた場合、顧客が発進して担当者が受けた場合。これだけの話に思えた。
しかし、実際は 以下の点で channel の入りが変わったりする。
- 通話が Twilio の Queue を使ったケース
- 通話が Twilio の Conference を使ったケース
- 通話を保留をして再開したケース
これら全てのケースを実際に録音通話で確認し、AWS 側では channel[0] か channel[1] かの振り分け結果を判断する必要があった。
研究した結果できるUI
全てが正しく保存できるようになったことが確認でき、実装することで、以下のようなUI を実現できる。
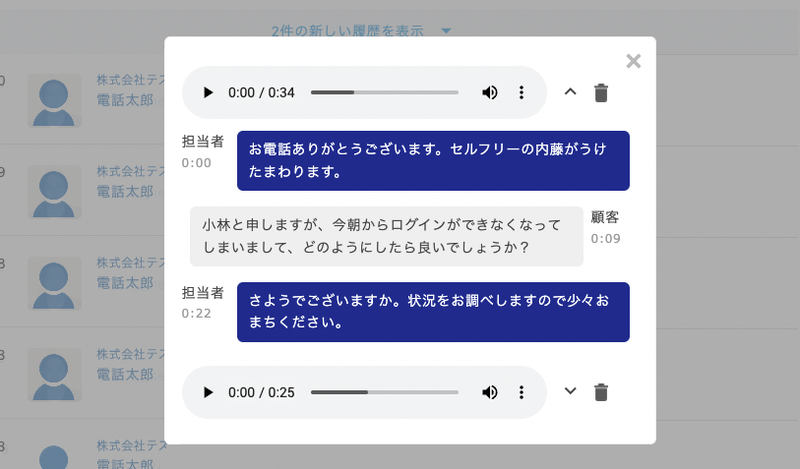
単に"どちらが" 何を言ったかがわかるだけなんだけども、今後の開発の中で "担当者が" 発言した中でのワード分析 など、分離ができることの影響は大きい。
終わりに
まだ音声テキスト変換の改善の序章に過ぎないが、1つ大きな進展ができたリリースをすることができた。
今後、この改善をベースにさらなる通話の分析ができるように、引き続きチャレンジしていこう。